Trusted Science. Delivered the Way You Need.
AbXtract™ Module for Sequence Analysis
Analyze your Next Generation Sequencing (NGS) and Sanger data on the cloud with the Orion® molecular design platform. These capabilities are part of AbXtract™, a module within Orion's Antibody Discovery Suite. AbXtract was developed in partnership with Specifica, founded by Andrew Bradbury, PhD, an innovator in novel antibody technologies. Contact us for a demo on how AbXtract can help you obtain potent leads with the most favorable developability and biophysical profiles.
Compared to conventional colony screening methods, NGS screening with AbXtract helps teams:
- Uncover more leads. Increase the number of clonotype leads five- to ten-fold compared to random colony screening
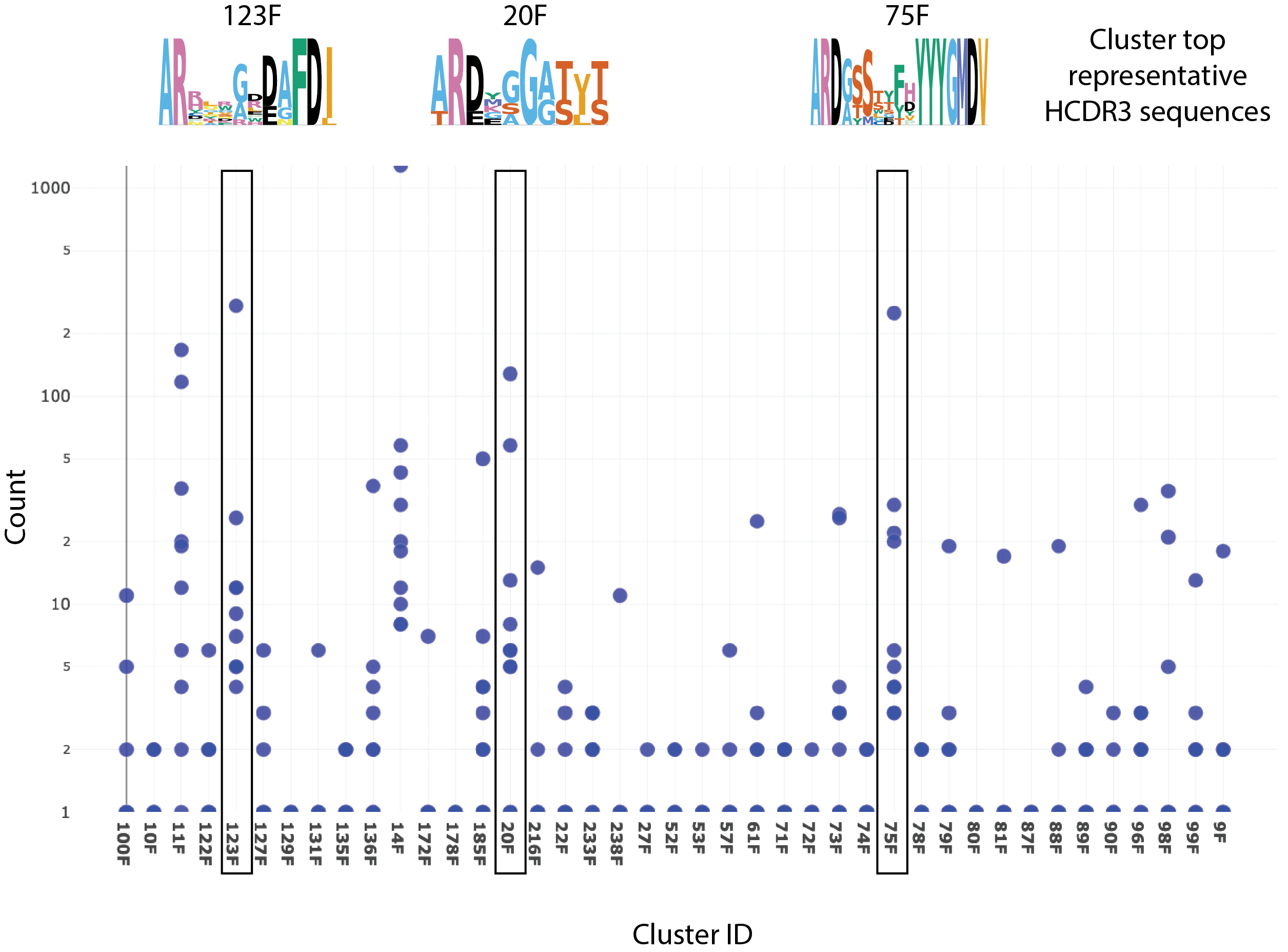
- Increase sequence diversity and cluster representation. Explore the entire sequence diversity within selected populations, even rare clones that are typically missed by low-throughput methods that favor more abundant antibodies
- Prioritize promising leads. Tie in known data, and even low-throughput assay data, to prioritize leads with the most favorable developability and biophysical profiles
- Minimize costs. Achieve high throughput for a fraction of the cost of conventional assay runs
- Equip the entire discovery team. Automated workflows for novice users, while allowing expert users to fully configure their settings
Antibody discovery projects that were previously out of reach because of software, hardware, computation, or data sharing limitations have now become possible with AbXtract on Orion. -- Andrew Bradbury, PhD, Specifica
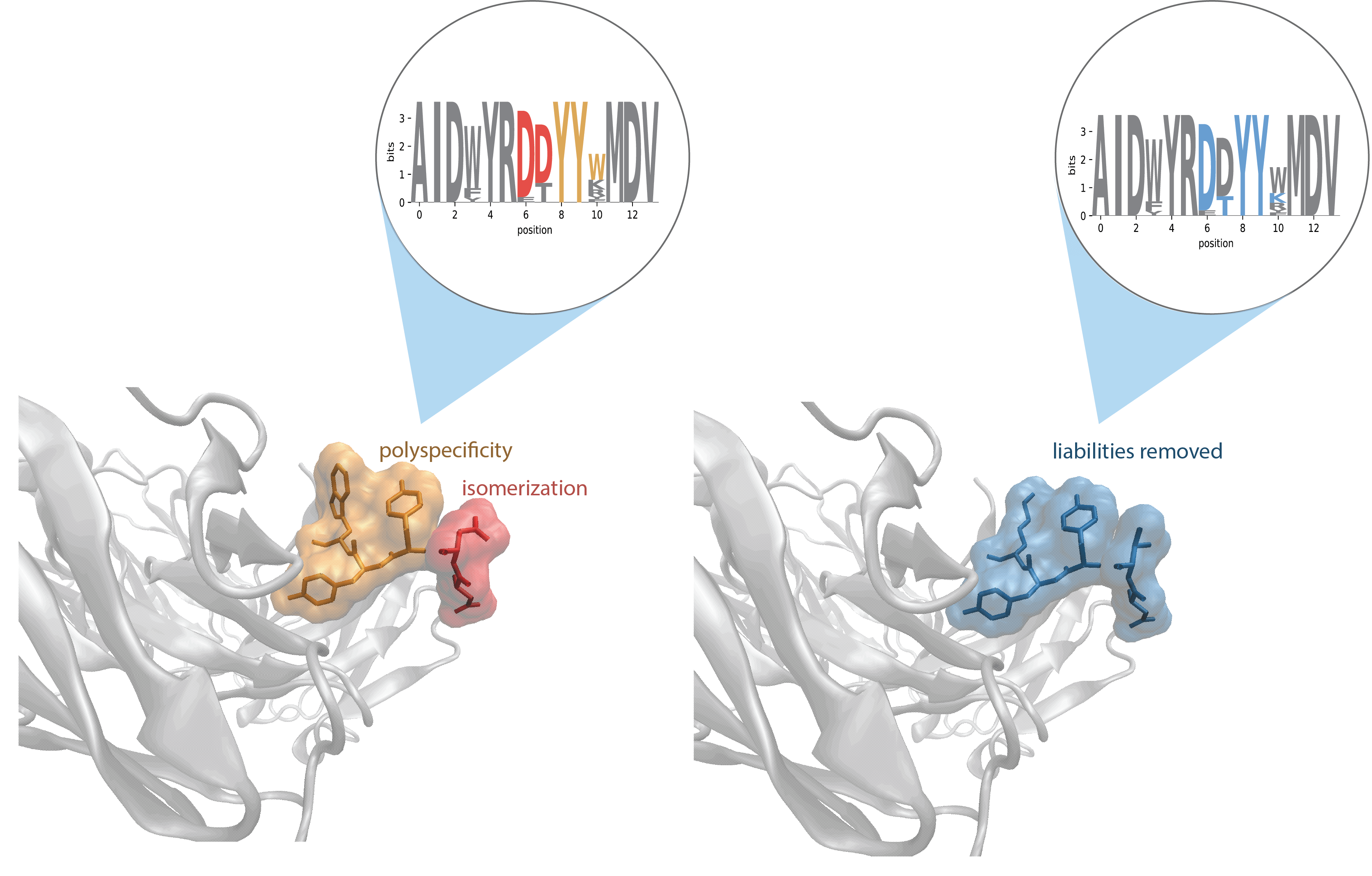
From Millions of Sequences to a Select Few
AbXtract has the cloud-based compute power to process tens of millions of sequences into meaningful information. Its sophisticated machine-learning algorithms and workflows help antibody engineers and bioinformaticians parse through this vast amount of data to characterize sequences and extract sequence- and functional-based features. Once promising leads are identified, visual models can further aid in decision-making.