Lexichem TK
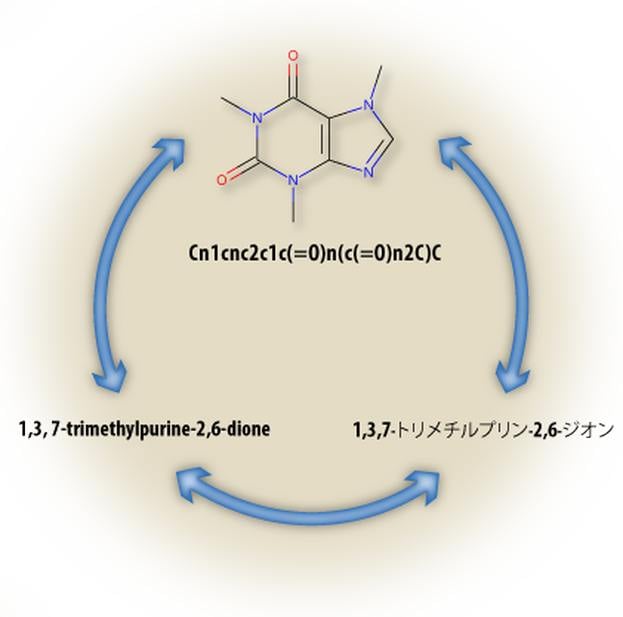
Chemical compound names remain the primary method for conveying molecular structures between chemists and researchers. In research articles, patents, chemical catalogues, government legislation, and textbooks, the use of IUPAC and traditional compound names is universal, despite efforts to introduce more machine-friendly representations such as identifiers and line notations.
The Lexichem TK provides an efficient and highly reliable platform for the interconversion of chemical structures and chemical names [1]. In addition, it also uniquely automates the foreign language translation of chemical nomenclature which is important due to the significant fraction of chemical literature that does not use English nomenclature [2]. This functionality reduces the complications associated with the tasks of filing and analyzing chemical patents, purchasing from compound vendors, and text mining research articles or Web pages.
Support nomenclature
- IUPAC 79 / 93 / 200x
- Chemical Abstracts / CAS
- Traditional
- Systematic
- MDL/Beilstein
- AutoNum
- OpenEye
Supported languages
- English (American, British, International)
- Japanese
- Chinese
- German
- Polish
- Hungarian
- Spanish
- Russian
- Italian
- Swedish
- French
- Slovak
- Romanian
- Danish
- Dutch
- Greek
For more detailed information on Lexichem TK, check out the link below: